Асинхронная загрузка данных в IBProvider
Привет всем.
На сайт загружены дистрибутивы нового триала IBProvider-a (v3.14), в котором реализована полноценная поддержка асинхронной загрузки результирующего множества.
Классическая, синхронная схема загрузки, подразумевает такую структуру временных затрат.
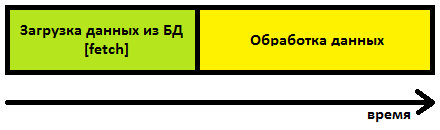
При асинхронной загрузке данных, грубо говоря, общее время работы определяется продолжительностью более затратной части процесса.
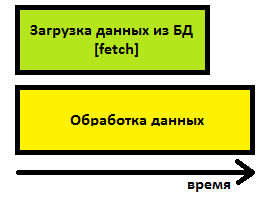
Для конфигурирования и контроля асинхронной загрузки результирующих множеств, в OLEDB определены следующие конструкции:
Свойство набора рядов «Asynchronous Rowset Processing». Это комбинация флагов, которая включает и настраивает асинхронную работу. В целом, что касается конфигурирования загрузки, выделим два режима:
- Блокирующая выборка данных.
- Неблокирующая выборка данных.
При блокирующей выборке, пользователь будет ждать до тех пор, пока не будет доступно запрошенное число рядов или будет достигнут конец результирующего множества.
При неблокирующей выборке, пользователь ограничится количеством рядов загруженными на текущий момент. И если это количество меньше, чем он запрашивал, то код завершения выборки будет равен DB_S_ENDOFROWSET.
Интерфейс IDBAsynchStatus. Этот интерфейс предоставляет пару методов для опроса состояния асинхронной операции и её отмены.
Интерфейс ISSAsynchStatus. Специализированный COM-интерфейс, определенный в SQLNCLI (это нативный клиент для MSSQL). Он наследует IDBAsynchStatus и определяет метод для ожидания завершения асинхронной операции.
Интерфейс IDBAsynchNotify. Это интерфейс точки подключения к уведомления асинхронной операции. Через эти уведомления можно отслеживать загрузку новых данных, завершение загрузки и узнавать о нехватке ресурсов.
Подключаются к этим уведомлениям стандартным способом — через IConnectionPointContainer и IConnectionPoint.
IBProvider поддерживает блокирующую и неблокирующую загрузки. Реализованы интерфейсы IDBAsynchStatus и ISSAsynchStatus. И поддерживаются уведомления через IDBAsynchNotify.
На что следует обратить внимание.
Хранение данных. Как синхронная, так и асинхронная загрузки данных используют продвинутые хранилища рядов с поддержкой параллельного доступа на базе временных файлов.
В случае Forward-Only Read-Only режима набора рядов, если пользователь не будет успевать выгребать из кэша асинхронно загружаемые данные, провайдер может начать выгружать записи во временный файл.
Объем памяти под кэш данных конфигурируется через свойство Memory Usage.
Отложенная загрузка блобов и массивов. По-умолчанию, провайдер не загружает данные блобов и массивов в процессе выборки (фетче) рядов результирующего множества. В случае асинхронной загрузки это означает то, что пользователь будет сам загружать эти данные из БД в своем потоке. Если такое положение дел не устраивает, нужно установить свойство deferred_data равным нулю. Будет задействовано специализированное хранилище (к примеру — такое), которое закэширует все данные множества.
Асинхронные уведомления. Было бы неразумно в процессе асинхронной загрузки синхронно уведомлять подписчиков о прогрессе операции. Поэтому в провайдере используются асинхронные уведомления.
Перейдем от слов к небольшой демонстрации. В этом примере
- Подключаемся к базе. В моем случае она на другом физическом компьютере.
- Выполняем подсчет записей в таблице (~680 тысяч). Серверная сторона осуществит кэширование данных.
- Созданием команду для запроса и конфигурируем объем памяти под кэш результирующего множества (1MB).
- Выполняем синхронную загрузку и перебор записей без чтения данных (test_func__fetch).
- Выполняем синхронную загрузку и перебор записей с чтением данных (test_func__fetch_and_read).
- Выполняем асинхронную загрузку и перебор записей с чтением данных (test_func__fetch_and_read).
- Сравниваем затраты 5 и 6 пунктов.
Кроме того, тест еще выводит служебную информацию о размере кэша и об использовании временного файла.
option explicit
const adAsyncFetch=32 '0x20
MsgBox "Stop"
call wscript.quit(main())
'---------------------------------------
function main()
main=0
dim cn
set cn=createobject("ADODB.Connection")
cn.Provider="LCPI.IBProvider.3"
cn.Properties("location")="home2:d:\database\re48120.gdb"
cn.Properties("ctype")="win1251"
cn.Properties("user id")="gamer"
cn.Properties("password")="vermut"
cn.Properties("auto_commit")=true
cn.Properties("dbclient_library")="fbclient.dll"
wscript.echo "Connect to database"
call cn.Open()
wscript.echo "Provider File : "& _
cstr(cn.Properties("Provider Name").Value)
wscript.echo "Provider Version: "&_
cstr(cn.Properties("Provider Version").Value)
wscript.echo ""
wscript.echo "First scan of test table"
wscript.echo "Rows count: "& _
cstr(cn.Execute("select count(*) from PEOPLE")(0).Value)
dim cmd
set cmd=createobject("ADODB.Command")
set cmd.ActiveConnection=cn
cmd.CommandText= _
"select ID,CLASS,FAMILY,NAME,LASTNAME"&vbCrLf& _
"from PEOPLE"
cmd.Properties("Memory Usage")=1*1024 '1 MB
'------------ fetch only
call run_test("Synch fetch only", _
getref("test_func__fetch"), _
cmd.Execute())
'------------ fetch and read data
dim d1,d2
d1=run_test("Synch load", _
getref("test_func__fetch_and_read"), _
cmd.Execute())
d2=run_test("Asynch load", _
getref("test_func__fetch_and_read"), _
cmd.Execute(,,adAsyncFetch))
wscript.echo ""
wscript.echo "profit: "&(((d1-d2)*100)/d2)&"%"
end function 'main
'---------------------------------------
function run_test(sign,test_func,rs)
wscript.echo ""
wscript.echo sign
dim ts1
ts1=Now()
wscript.echo "Start : "&FormatDateTime(ts1,3)
dim n
n=test_func(rs)
dim ts2
ts2=Now()
wscript.echo "Stop : "&FormatDateTime(ts2,3)
dim d
d=DateDiff("s",ts1,ts2)
wscript.echo "Duration: "&cstr(d)&" second(s)"
wscript.echo "Fetched : "&cstr(n)&" row(s)"
dim stg_size
stg_size=rs.Properties("IBP_RS_INFO: Result Storage Size").Value
dim use_tmp_file
use_tmp_file=rs.Properties("IBP_RS_INFO: Using File Storage").Value
wscript.echo "Stg size: "&cstr(clng(clng(stg_size)/1024))&" KB"
wscript.echo "Use file: "&GetYesNo(use_tmp_file)
run_test=d
end function 'run_test
'---------------------------------------
function test_func__fetch(rs)
dim n
n=0
while(not rs.eof)
n=n+1
call rs.MoveNext()
wend
test_func__fetch=n
end function 'test_func__fetch
'---------------------------------------
function test_func__fetch_and_read(rs)
dim e,n,i,v
e=rs.Fields.Count-1
n=0
while(not rs.eof)
n=n+1
for i=0 to e
v=rs(i).value
next 'i
call rs.MoveNext()
wend
test_func__fetch_and_read=n
end function 'test_func__fetch_and_read
'---------------------------------------
function GetYesNo(v)
if(v)then
GetYesNo="Yes"
else
GetYesNo="No"
end if
end function 'GetYesNo
Вывод:
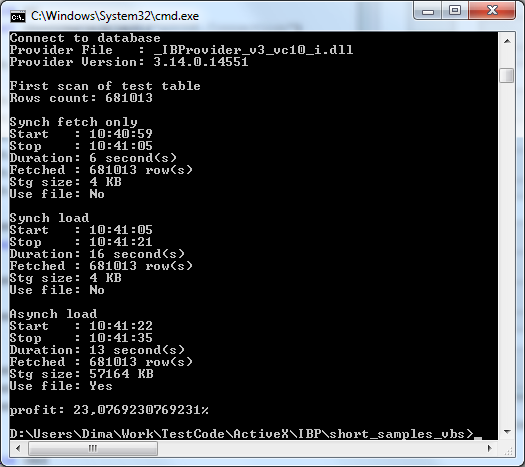
При синхронной загрузке данных временный файлы не создаются и размер кэша составляет минимальные 4KB (1 страница процессора). При асинхронной загрузке у нас будет создан временный файл, размером порядка 57MB.
В Process Explorer работа процесса выглядела так:
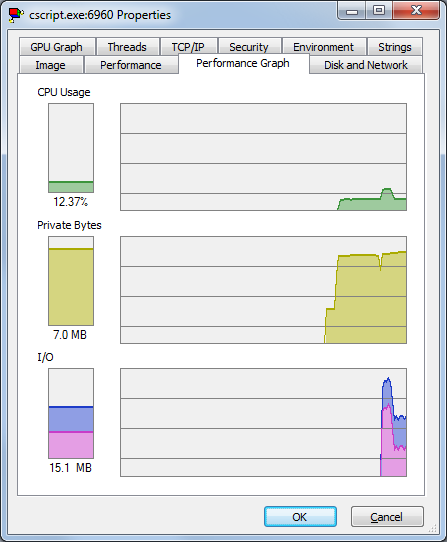
С момента появления «горбика» в графике утилизации процессорного времени начинает работать асинхронная загрузка данных. Поскольку загрузка из БД значительно опережает обработку данных, провайдер начинает сбрасывать данные на диск. После завершения асинхронной загрузки (загрузка процессора падает до 12%) выборка идет из локального временного файла.
Итоговый выигрыш от использования асинхронной загрузки составил 3 секунды (или 23% для данной обработки данных).
В довесок к предыдущему, искусственному примеру, посмотрим на результаты, полученные в нашей тестовой системе. Она более приближена к реальной жизни.
Сервер (суперклассик FB2.5.x) и тестовая система разнесены по разным физическим компьютерам с четырех-ядерными процессорами.
Сравниваем реальное время работы следующих групп по 320 тестов
- octets.002.array.synch.ro_v2.cmd.*CHAR_ARRAY__32.*
- octets.002.array.asynch.ro_v2.cmd.*CHAR_ARRAY__32.*
Тесты создают/загружают и проверяют/удаляют достаточно большие наборы (размером по 4081 или 8161) записей с с массивами.
Получились такие цифры:
Синхронная загрузка
[summary] REAL : 9145503090 [00:15:14.5503090]
[summary] USER : 1048794723 [00:01:44.8794723]
[summary] KERNEL : 448034872 [00:00:44.8034872]
[summary] TOTAL : 1496829595 [00:02:29.6829595]
Асинхронная загрузка
[summary] REAL : 8946441712 [00:14:54.6441712]
[summary] USER : 864557542 [00:01:26.4557542]
[summary] KERNEL : 327446099 [00:00:32.7446099]
[summary] TOTAL : 1192003641 [00:01:59.2003641]
Здесь
- REAL — это реальное время которое было потрачено тестами.
- USER/KERNEL/TOTAL — это процессорное время, потраченное тестовыми потоками. Сюда включено время потраченное провайдером, когда в него заходит тестовый поток. И не учитывается время, которое съедают фоновые потоки провайдера.
Выигрыш составил 20 секунд. Немного. Но с учетом того, что
- Работа шла по сети.
- В это время включены затраты на добавление и удаление записей.
- Данные содержат массивы, работа с которыми относительно медленная.
- Процессор тестовой машины простаивал в обоих случаях (см. на TOTAL).
неплохо. А можно сравнить процессорное время тестовых потоков и обнаружить 25% выигрыш 🙂
В итоге
У провайдера появился еще один механизм, упрощающий создание высокопроизводительных приложений. Можно, конечно, и самому распараллеливать работу с БД. Но на это не всегда есть время. А иногда — крайне затруднительно. А здесь предлагается готовое, отлаженное и стандартное решение. Затраты на использование которого сводятся к установке значения одного свойства (Asynchronous Rowset Processing). Ну или, в случае ADODB — к передаче флага adAsyncFetch в Command.Execute. И вперед — в мир параллельных вычислений 🙂
На этом пока все.